Selected Publications
For a full list, have a look at my Google Scholar page.

ShotAdapter: Text-to-Multi-Shot Video Generation with Diffusion Models
A framework that enables text-to-multi-shot video generation with shot-specific conditioning and full attention across all frames.
O. Kara, K. Singh, F. Liu, D. Ceylan, J. M. Rehg, T. Hinz, Conference on Computer Vision and Pattern Recognition 2025.

Personalized Residuals for Concept-Driven Text-to-Image Generation
A novel and efficient approach for enabling personalized image generation with diffusion models.
C. Ham, M. Fisher, J. Hays, N. Kolkin, Y. Liu, R. Zhang, T. Hinz, Conference on Computer Vision and Pattern Recognition 2024.
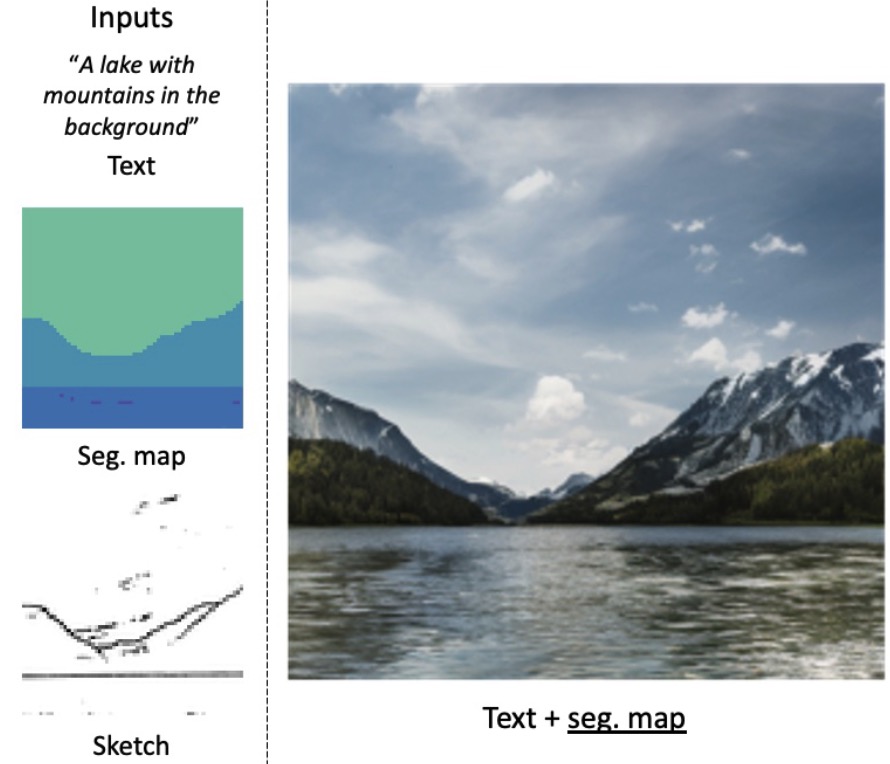

SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model
A diffusion model for shape-guided inpainting with better shape control and background preservation within the inpainted region.
S. Xie, Z. Zhang, Z. Lin, T. Hinz, K. Zhang, Conference on Computer Vision and Pattern Recognition 2023.

ASSET: Autoregressive Semantic Scene Editing with Transformers at High Resolutions
A neural architecture for automatically modifying an input high-resolution image according to a user's edits on its semantic segmentation map.
D. Liu, S. Shetty, T. Hinz, M. Fisher, R. Zhang, T. Park, E. Kalogerakis, ACM Transactions on Graphics (SIGGRAPH 2022) 2022.




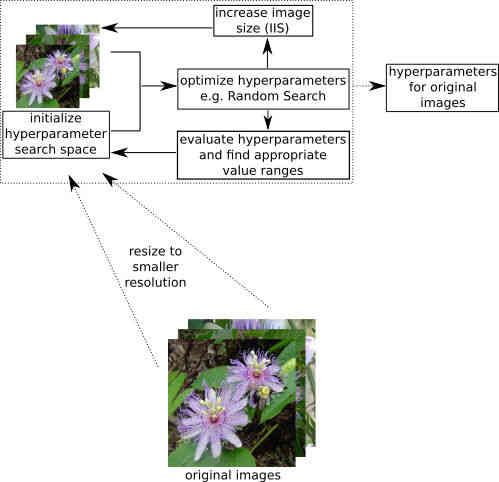
Speeding Up the Hyperparameter Optimization Of Deep Convolutional Neural Networks
How to use lower dimensional data representations to speed up the hyperparameter optimization for CNNs processing images..
T. Hinz, N. Navarro-Guerrero, S. Magg, S. Wermter, International Journal of Computational Intelligence and Applications 2018.


The Effects of Regularization on Learning Facial Expressions with Convolutional Neural Networks
How modern regularization techniques for CNNs affect the learned representations.
T. Hinz, P. Barros, S. Wermter, International Conference on Artificial Neural Networks 2016.
Back to Home