Introduction
Richard Feynman: What I cannot create, I do not understand.
One of the goals of generative models in machine learning is to model (and sample from) complex, unknown data distributions. As such, generating (and therefore modeling) images has become a popular task for generative models. This is mostly due to increased computing power and novel models (such as Generative Adversarial Nets and Variational Autoencoders) that are “good” at modeling images. Additionally, we have a lot of images available to us (i.e. lots of training data) and images represent a reasonably complex data distribution1.
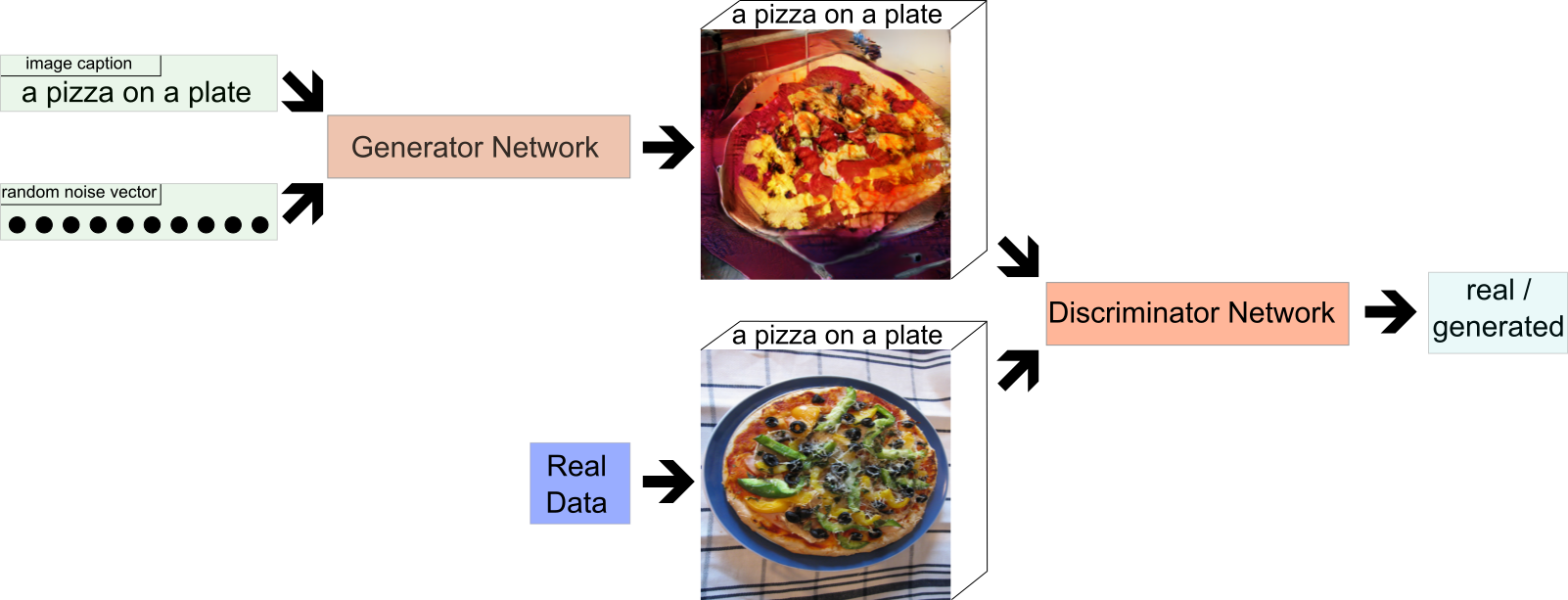
Currently, Generative Adversarial Nets (GANs) are one of the models that tend to produce the sharpest images. A GAN typically consists of two neural networks (see Figure 1): a generator network which generates images and a discriminator network which tries to distinguish between real images and the images generated by the generator. The generator gets as input a randomly sampled noise vector (and possibly additional information about the image such as a textual description) and applies a number of transforms to generate an image from it. The discriminator gets as input either a “real” image from the data set we work with or an image that was generated by the generator (along with the additional information that was also given to the generator).
The discriminator’s goal is to distinguish between real and generated images, while the generator’s goal is to “fool” the discriminator, i.e. to generate images that are indistinguishable from real ones. This results in a competition between the two networks and both networks are typically trained in an alternating manner to get better at their respective goals. The end result (ideally) is a generator that can generate images that are indistinguishable from real images.
However, most current GAN models focus on modeling images that either contain only one centralized object (e.g. faces (CelebA), objects (ImageNet), birds (CUB-200), flowers (Oxford-102)) or on images from one specific domain (e.g. LSUN bedrooms or churches). This means that, overall, the variance between images used for training GANs tends to be low, while many real-life images tend to depict complex scenes with different objects at different locations.

The MS-COCO data set (see Figure 3 for example images) consists of more than 100,000 images of “Common Objects in COntext” and has a high variability in its image contents. Each image is associated with five captions that describe the image. In order to model images with complex scenes like in the MS-COCO data set, we need models that can model images containing multiple objects at distinct locations. To achieve this, we need control over what kind of objects are generated (e.g. persons, animals, objects), the location, and the size of these objects.

Current work often approaches this challenge by using a scene layout as additional conditional input to the model. A scene layout basically defines the structure of a given scene on a high-level, abstract basis and describes where in the image certain objects should be located. GANs that make use of these layouts therefore have more information about the image they should generate and we can control the image generation process by adapting the individual scene layouts. However, in order to train these models we need images with a known scene layout, which is usually obtained by having humans annotate images. As a result, many of the recent models are trained on the COCO-Stuff data set (see Figure 4), which augments the MS-COCO data set with pixel-level annotations.

Our work takes a similar approach, but instead of needing a complete scene layout for each image during training we only require the location of “salient” objects within the image (see Figure 5), while the rest of the scene (e.g. the background) is generated automatically. This reduces the amount of labels we need for our training images. Additionally, it also makes it easier to modify the layout of an image, since all we have to do is move around the location of the objects whose location we want to change, while the model will keep the background and the relationships between the objects coherent without further instructions.

The MS-COCO data set already provides bounding boxes for many objects within the image, encompassing 80 different object categories such as persons, animals, and cars. We can use these bounding boxes and their respective object category to determine the location and identity of objects within images and use this for training our model.
Methodology
Our model is a GAN as depicted in Figure 1 with some architectural adaptations (see Figure 6). We extend both our generator and our discriminator with an object pathway which is responsible for modeling the individual objects we encounter during training2. The global pathway, on the other hand, takes care of the image background and ensures the overall image consistency. The figure below gives a high-level overview of our model.
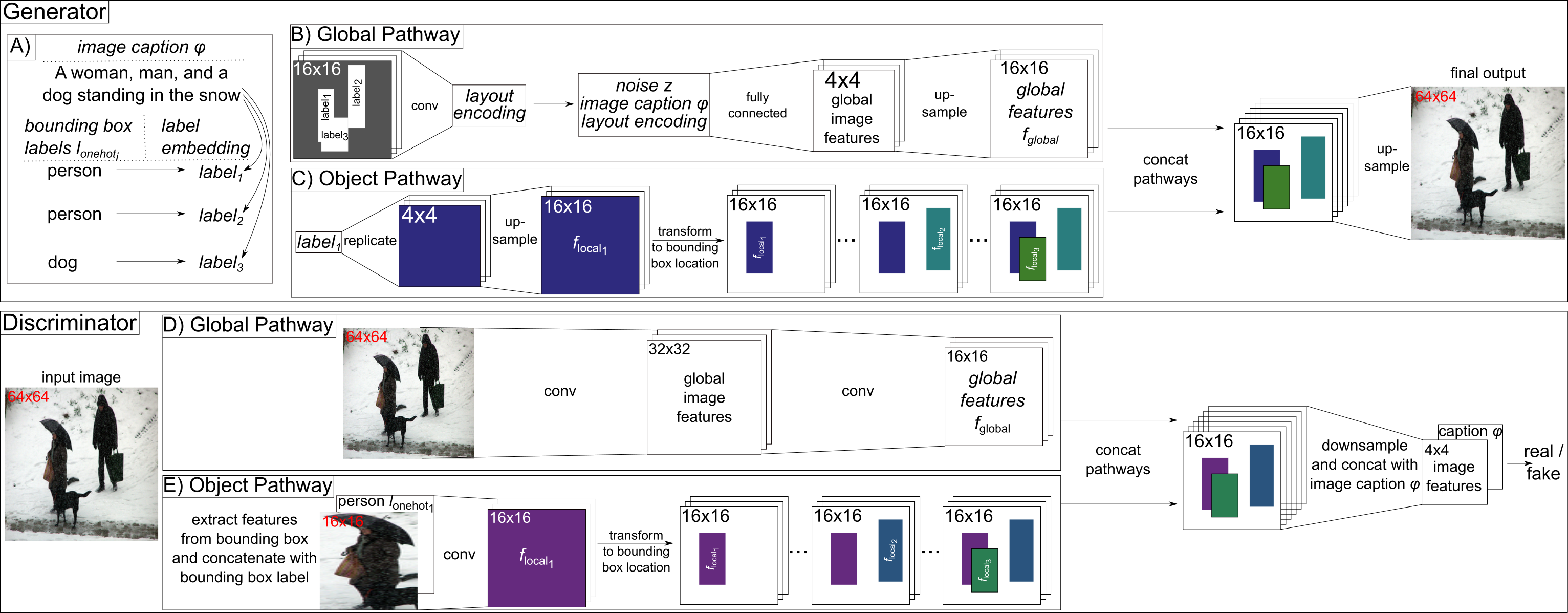
Generator
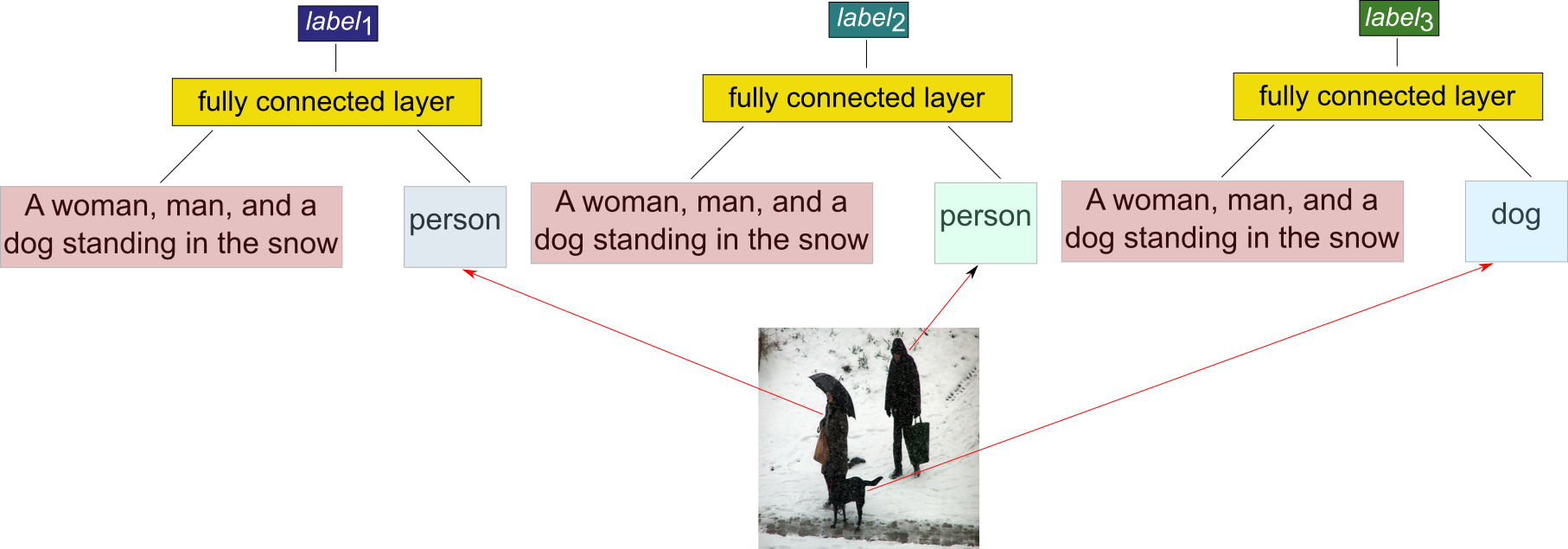
We first create a label for each salient object within the image. For this we use the caption embedding for this image (i.e. the image caption is represented as a vector) and concatenate it with the label (encoded as a one-hot vector) for the given object (e.g. “person”). From this we obtain a label embedding for the given object by applying a matrix multiplication and a non-linearity (i.e. a fully connected layer). By combining the image caption and the object label to generate the final label the network can incorporate additional information (such as shape or color, which is not obtainable from the object label itself) into the final label.
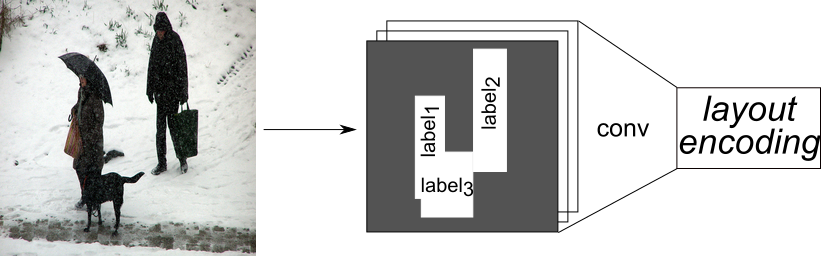
Once we have a label for each of the objects we want to model we continue with the global and object pathway. The global pathway first creates a layout encoding (Figure 8) which encodes the general scene layout, i.e. the location and object category of the different objects we want to model. To obtain the layout encoding we spatially replicate the previously obtained labels for each of the objects at the locations of their bounding box within an empty image. The resulting layout is then encoded with a convolutional neural network (CNN).
This layout encoding is then concatenated with the image caption embedding and the randomly sampled noise vector and we then apply multiple convolutional layers with intermediate nearest neighbor upsampling to obtain a representation of the global image background.

In parallel, the object pathway gets as input the first of the previously generated object label and uses it to generate a representation of this object. This object representation is then added to an empty image at the location of the object’s bounding box (Figure 10). We repeat this for each of the object labels until we have an image that contains the object representations at the given bounding box locations.
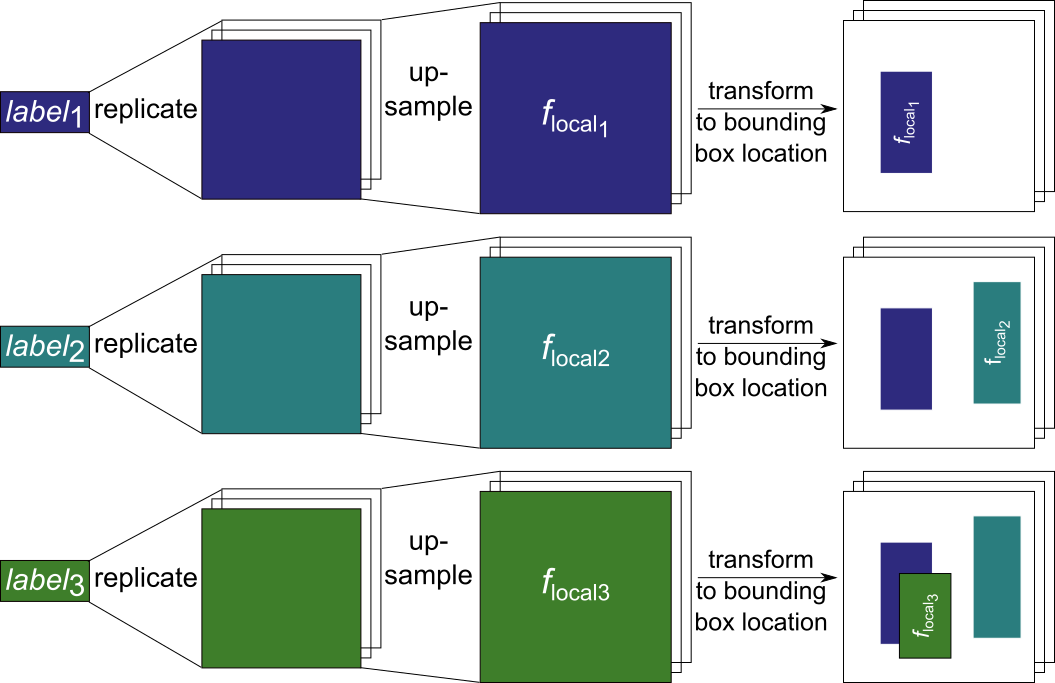
As a final step, we concatenate the output of the global and object pathways and apply more convolutional layers with intermediate nearest neighbor upsampling to obtain a the final image for the given image caption and bounding box locations.

Discriminator
The discriminator also consists of a global and an object pathway.
The global pathway uses a CNN to obtain a global feature representation of the whole image.

The object pathway is again applied to each of the objects individually. We extract the first object from the image and concatenate it with the object category for this object (e.g. “person”). We then apply a CNN to obtain a feature representation of the given object, which is placed at the location of the bounding box on an empty image. This is done for each of the objects within the image and results in an image that contains the object features of the given objects at their given location.

Finally, the outputs of the object and global pathways are again concatenated and processed by a CNN. At the end, the features from the CNN are concatenated with the given image caption embedding and the resulting tensor is classified as either generated or real.

Training
For the general training, we can utilize the same procedure that is used in the GAN architecture that is modified with our proposed approach. As previously described, the generator is trained to generate images that fool the discriminator, while the discriminator is trained to distinguish between real and generated images. For more information about the training see the Approach section and the Appendix of our paper, as well as the code in our Github.
Evaluation
Evaluating generative models is a notoriously hard task for which it is difficult to find good quantitative metrics3. We first trained our model on two synthetic data sets (Multi-MNIST and CLEVR) and evaluate it qualitatively on different subsets of these data sets. Following this, we trained our model on the MS-COCO data set and evaluate it qualitatively and quantitatively. For the quantitative evaluation we use the Inception Score (IS) and the Fréchet Inception Distance (FID), as well as a novel evaluation metric based on how often a pre-trained object detector detects a given object in our generated images.
Multi-MNIST
On the Multi-MNIST data set we use training images that contain three digits at non-overlapping positions.
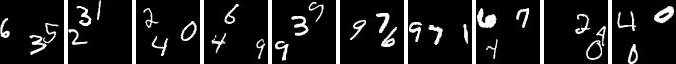
After the training was finished we can use our model to generate new images in which we can specify where a digit should occur and what kind of digits should be generated. Even though our training images only consisted of images that contained exactly three digits our model is able to generate images with various amounts of digits:
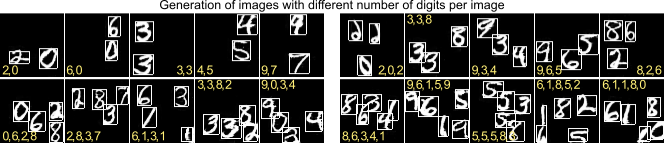
Furthermore, we can also change the size of the digits within the images:

We also performed ablation studies in which we trained the model without some of the extensions, e.g. without the layout encoding in the generator’s global pathway or without the object pathway in either the generator or the discriminator. We found that all of the extensions were necessary to achieve optimal performance and refer to our paper for more details.
CLEVR
The CLEVR data set consists of images which contain different objects (cylinders, cubes, and spheres) of different sizes, colors, and materials at different locations.

We rendered images that contain 2-4 objects at various locations and again trained our model. After the training was finished we can generate images in which we can control different aspects (object category, color, location, and size) of the objects. As before, we can also generate images that contain more objects in an image than were observed during training.

To test the generalization capabilities of our model we also used an adapted version of the CLEVR data set (CLEVR CoGenT) in which some color-object combinations only occur in either the training or the test set. Specifically, in the training set cubes are either gray, blue, brown, or yellow, while cylinders are either red, green, purple, or cyan. In the test set these combinations are inverted. Spheres can have either color in both the training and the test set. We can see that our model is able to generalize to novel object-color combinations, even though we can observe some minor artifacts.

Overall, the experiments on the synthetic data sets indicate that our model is able to control the location and various other characteristics of individual objects. It can also generalize to previously unseen object characteristics, unseen locations (if the location has been observed for another object during training) and to unseen numbers of objects. To further test the model’s capabilities we now proceed with a more complex data set.
MS-COCO
To evaluate our model on real world images we trained it on the MS-COCO data set. For each image we take the three biggest objects (based on their bounding boxes) as long as they cover at least 2% of the total image each. As a result, our training data consists of images with their associated captions and 0-3 labeled objects for the object pathways.
After the training was finished we evaluated the generated images qualitatively to check if objects are placed at the requested locations. We can see that the images indeed contain objects at the given locations.

To evaluate the impact of the global and the object pathway we can generate images while switching either the global or the object pathway off. We can see that the global pathway does indeed focus on the background of the image, but mostly ignores the high level objects at the given location. These are modeled by the object pathway, as can be seen in the last row.

To evaluate our model quantitatively we used the Inception Score (IS) and the Fréchet Inception Distance (FID). The IS tries to evaluate how recognizable and diverse objects within images are, while the FID compares the statistics of generated images with real images. We observe improvements in both the IS and the FID when comparing our model to the baseline models without an object pathway, as well as to other models4. Note, however, that the IS and FID values of our model are not directly comparable to the other models, since our model gets at test time, in addition to the image caption, up to three bounding boxes and their respective object labels as input.
In order to further evaluate the quality of our model, we ran an object detection test on the generated images using a pre-trained YOLOv3 network. For this, we evaluated how often the pre-trained YOLOv3 network recognizes a specific object within a generated image that should contain this object based on the image caption. For example, we expect an image generated from the caption “a young woman taking a picture with her phone” to contain a person somewhere in the image and we check whether the YOLOv3 network actually recognizes a person in the generated image. We also calculated the Intersection over Union (IoU) between the ground truth bounding box (the bounding box supplied to the model) and the bounding box predicted by the YOLOv3 network for the recognized object. We tested the model’s performance with the 30 most common object labels based on their number of occurrences in captions in the test set5.
Our results show that the object pathway seems to improve the image quality, since YOLOv3 detects a given object more often correctly when the images are generated with an object pathway as opposed to images generated with the baseline model without an object pathway. Our model also succeeds in placing the objects at the specified locations, with one model architecture reaching an an IoU of greater than 0.3 for all tested labels and greater than 0.5 for 86.7% of the tested labels.
Future Work
While the overall results are promising, there are still some issues that need to be addressed in future work. First of all, our model has problems when the bounding boxes of two objects overlap to a high degree (empirically an overlap of more than 30% leads to a drop in performance). This is most likely due to the fact that the features and labels in the overlapping parts of the bounding boxes are simply summed up during training and inference. This could be addressed by more sophisticated approaches, such as normalizing the embeddings or taking their average.
Secondly, the dependence of our model on the object pathway can lead to sub-optimal results if there are no bounding box locations for objects within the image. Since the global pathway relies on the object pathway for the object features this can lead to images which only depict background but do not contain obvious objects from the image caption, if the object pathway is not used for these objects (e.g. because they are too small).

Another issue is the generalization of objects to previously unseen locations. Experiments on the Multi-MNIST data set show that the model in its current form is unable to generalize objects to locations at which it has not seen any object during training. When we train the model with images that do not contain any digits in the lower half of the image, the model also fails to generate images that contain digits in the lower half of the image.

However, our model is able to generalize objects to locations at which it has not observed that specific object before, as long as other (similar) objects have been observed at that location. We trained our model with images that contain only the digits {0,1,2,3,4} in the top half of the image and only digits {5,6,7,8,9} in the bottom half of the image. After training, the model is capable of generating images that contain digits 0-4 also in the bottom half of the image and digits 5-9 in the top half.

Finally, at the moment our model needs the object categories and the bounding boxes in addition to the image caption to generate images, which somewhat limits the usability for unsupervised image generation. In the future, this limitation could be avoided by extracting the relevant bounding boxes and labels directly from the image caption, as it is done for example by Hong et al., Xu et al., and Tan et al.
You can download the models and generate new images for yourself. You can find the code, data sets and pre-trained models on our Github page. If you have any more questions or feedback feel free to contact me via [email protected].
1: it also means we can put cat pictures into scientific papers, which is awesome.
2: Reed et al. propose a similar architecture, but focus only on one individual object within an image. For more details on the differences please see our paper.
3: see here for an overview of the pros and cons of different evaluation metrics for GANs
4: please refer to Table 1 of our paper for more details
5: for more details on the exact procedure as well as more detailed results please see the Appendix of our paper