Impressions and Highlights from the ICLR 2019 in New Orleans
Tobias Hinz
15 May 2019
Reading time: 18 minutes
This is a summary of my impressions from this year’s ICLR, which took place in New Orleans from the 6.-9. May and where I presented our work on GANs. The first part of this post covers my general impressions and is entirely based on my personal views and experiences. The second part covers some of the work that I found particularly interesting. Note that the second part is mostly based on topics that I am personally interested in and that I am unfortunately not able to cover all of the presented work (e.g. I skipped most works on Reinforcement Learning).
Tweeting this week from #iclr2019 and what is packed week of all things machine learning. pic.twitter.com/tKxUvZkmhs— Shakir Mohamed (@shakir_za) 6. Mai 2019
For a nice, one-sentence summary of all accepted papers check out the summaries from Paper Digest and many of the posters can be found here (thanks to Jonathan Binas and Avital Oliver for organizing this).
General impressions
The conference took place in the Ernest N. Morial Convention Center in New Orleans. It’s a nice convention center, located in the CBD of New Orleans, with plenty of space, a food court, Starbucks, and other amenities you might need.

The conference officially started on Monday, 6. May 2019. Luckily, I already picked up my badge on Sunday, which turned out to be a good move, since the queue on Monday morning was fairly long (at least at 8.30am when I arrived).
Someone thought they could have simply registered in the morning 🤣🤣🤣
Newbies! #ICLR2019 pic.twitter.com/iZmgYYTquK— Alfredo Canziani @ ICLR (@alfcnz) 6. Mai 2019
Alexander Rush officially opened the conference at 8.45am (before the first keynote at 9am). After some general statistics about the development of the conference (the number of submissions reached another all-time high of almost 1,500 including more than 6,000 authors, about 500 accepted papers, and more than 3,000 registered visitors) his main message was focused on inclusion and diversity.

This is one of the main reasons that the conference will take place in Africa next year, to acknowledge the small number of minorities present at large ML conferences. One of the big issues for many people is to obtain valid visas to enter the USA and Canada to visit conferences, and in fact, many researchers have not been able to obtain visas to visit last year’s NeurIPS and ICLR. Alexander also acknowledged that there was some backlash about the rights of the LGBTQ community in Africa and assured that the conference committee is in contact with the government in order to make all potential attendants feel welcome and safe.
ICLR 2020 will be in Addis! Exciting news not only to reduce the visa issues that have plagued recent conferences, but also because I think many of my colleagues will be inspired by the wave of AI used for good that is sweeping through Africa right now. https://t.co/T014bPe0g9— Sara Hooker (@sarahookr) 18. November 2018
The first day was a workshop day, along with two keynote talks and some oral presentations of accepted papers. This was the first time that all workshops took place on a single day instead of being distributed throughout the conference. The advantage of this was that each workshop was one continuous event without large breaks. As such, they had a nice “flow” to them and allowed for multiple invited speakers combined with poster presentations of accepted papers.
While I liked this format, the challenge here was the overlap of oral presentations and workshops. The workshops usually did not have a program during the keynote talks (i.e. everyone could listen to them without missing any of the workshops), however, the same was not true for the oral presentations of accepted papers. The workshops started (continued) right after the keynote speakers, so at this point, you had to decide whether to listen to the oral presentations (and miss parts of the workshops) or to go straight to the workshops and miss the oral presentation.
I chose to stay for the oral presentations (which were definitely worthwhile), but as a result, I missed out on some of the invited speakers in the workshops. Additionally, the rooms the workshops took place in were not the largest. The workshop rooms were also a fair distance away from the main halls and it took about 5 minutes to reach them. I mostly stayed with the “Learning from Limited Data” workshop (which was excellent), but the room was quite full and it was often hard to get a seat. Furthermore, the workshop about generative models was completely overcrowded. I tried to check it out three or four times, but could never get into the room.
The coffee breaks and the receptions took place in a big hall, which is also where all the sponsors had their booths. The catering for the coffee breaks was nice, with plenty of coffee (decaf was also available), snacks, fruit, and yogurt.


In fact, you could even get free massages!
Free back massage! 💆♂️❤️😍 #ICLR2019 pic.twitter.com/0h7yAKpOvB— Alfredo Canziani @ ICLR (@alfcnz) 6. Mai 2019
Overall, there were quite a number of sponsors at this year’s ICLR, reaching from well-known players (such as DeepMind, Google AI, Facebook, Salesforce, Microsoft, …) to vendors offering hardware solutions (e.g. Graphcore and Lambda), and even investment companies and other applied research companies. All sponsors had booths and people you could talk to and ask about the companies. Some companies were clearly there for recruiting purposes, while other companies had their booths stacked with research scientists so you could talk about their work and research.
At #ICLR2019? Visit the Google booth at 10:30 to check out MiniGo (https://t.co/T5lIrsK2g5), an open-source implementation of the @DeepMindAI AlphaGo Zero algorithm (https://t.co/gOK7r4RaKW) that learns by playing against itself, running on an Edge TPU (https://t.co/6q1d6lT4oW). pic.twitter.com/exnMYb8eUl— Google AI (@GoogleAI) 6. Mai 2019
Several booths also had nice presentations of their work (e.g. OpenAI had their latest language model there, the GPT-2, which would continue to write text given a prompt by you) and the possibility to talk to researchers about some of their projects.
Last chance to try out our language model, GPT-2, at ICLR 2019! Check it out at our booth - members of the OpenAI team are happy to chat and will be around until 5pmCT. pic.twitter.com/uJqVY6w7Pn— OpenAI (@OpenAI) 9. Mai 2019
Overall, the mood was usually quite relaxed and it was very easy to just walk up to any of the booths and get into a conversation with them.
The overall structure was the same for each day: the morning started with an invited keynote speaker at 9am, followed by 3-4 oral presentations of accepted papers (15 min per presentation) and a 30-minute coffee break. The mornings were then concluded with a two-hour slot for poster presentations before everyone went for a lunch break. The afternoon followed much the same structure with another invited keynote speaker, oral presentations, coffee break, and the poster presentations.
🧙🧙♂️🧙♀️ pic.twitter.com/AmyNx4jeAJ— ICLR 2019 (@iclr2019) 9. Mai 2019
This worked pretty well even though two hours are quite a short time to look at all presented posters (70-80 new posters per slot). Posters were also clustered so that each session represented (roughly) a given research direction. For example, Tuesday morning was focused on GANs while Tuesday evening was focused on adversarial attacks and defenses as well as robustness in general. The posters on Wednesday morning focused on Reinforcement Learning, continual and active learning, and meta-learning, while Wednesday evening targeted optimizers, (training) convergence, learning theory, compression, and quantization. Finally, Thursday morning showed posters about RNNs, NLP and language modeling, Seq2Seq models, and various “translation” tasks (TTS, language translation, Music, etc), and Thursday evening concluded with generative models, low precision training, meta-learning, domain adaptation, compression, BNNs, and Variational Bayes.

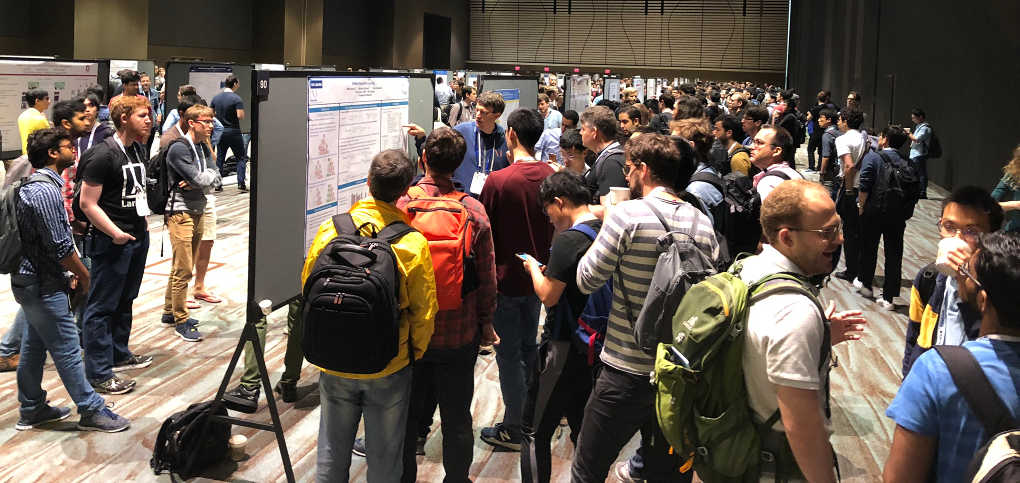
While I felt that this grouping was nice in that each poster session felt like one coherent session there was also some discussion about this form. Many people complained that the focus on one (or few) topic(s) per session made it impossible for a person specifically interested in one topic (say RL) to look at all posters of that topic. For example, a person mainly interested in RL had only two hours on Wednesday morning to go through (almost) all papers/posters about RL, which is not enough time if you really want to dig deeper into the content of multiple posters.

Another novelty at this year’s ICLR was an (industry) expo, which took place in the Tuesday lunch break, some of the sponsors introduced their work. Since I presented our poster on Tuesday morning from 11am-1pm I got to the event 15 minutes late but was still able to join the Google AI session with Pablo Castro about Machine Learning for Musical Creativity. The talk was about how we can use machine learning models to support people in the creative process of music generations. Overall, the presentation was quite entertaining and included a live presentation of the system towards the end.
Happening in 50 minutes in R09.
Come hear about some of my research on using machine learning for creative purposes, and come listen to me do collaborative musical improvisation with some #ML models!
🤖🎹🥁 https://t.co/EAqJN3wjK8— Pablo Samuel Castro (@pcastr) 7. Mai 2019
With all the science going on at the conference there was (of course) also a chance to party and to mingle outside of the conference center. Wednesday evening was the night of the sponsored parties, with companies like Salesforce, Microsoft, Facebook, and DeepMind all throwing their own party.
Amazing @HOBMusicForward bands at house of blues in New Orleans at our @SFResearch party #ICLR2019 pic.twitter.com/nTjNtwREBw— Richard Socher (@RichardSocher) 9. Mai 2019
Facebook party at ICLR.
Yes, with a jazz band. They played many styles, but they did play a couple hard bop tunes.— Yann LeCun (@ylecun) 9. Mai 2019
I went to an event hosted by DeepMind close to the Convention Center. There was live music, good food, and drinks. The event was on the smaller side which was actually nice since it really gave you a chance to talk to research scientists and engineers working for DeepMind. It felt like about half the attendants were DeepMind employees, so it was easy to get to talk to them. We spent the night talking about the conference, posters, papers, work at DeepMind, Tensorflow vs. PyTorch, and lots of other (un)related stuff.
Each day featured two keynote speakers. I attended most of them and found them insightful and interesting. Others have already done a good job at summarizing them so I will not talk about them here. See for example David Abel’s summary or this summary about Léon Bottou’s talk. You can also watch most of the talks here. This year there was also a debate moderated by Leslie Kaelbing about how much structure/priors/implicit knowledge we should implement in our models. The debate was led by Doina Precup, Jeff Clune (both advocate learning as much as possible from data), Suchi Saria, and Josh Tenenbaum (who advocate for the advantages of using priors in our models). The debate was quite entertaining (especially the second half) and you can watch it here (starts at around 23 min).

The debate also allowed for interaction with the audience, who could ask (and upvote) questions online. While a lot of people used the platform to ask questions, some people also posted questions under the name of famous (at least in the community) people (you could write any name when asking a question).
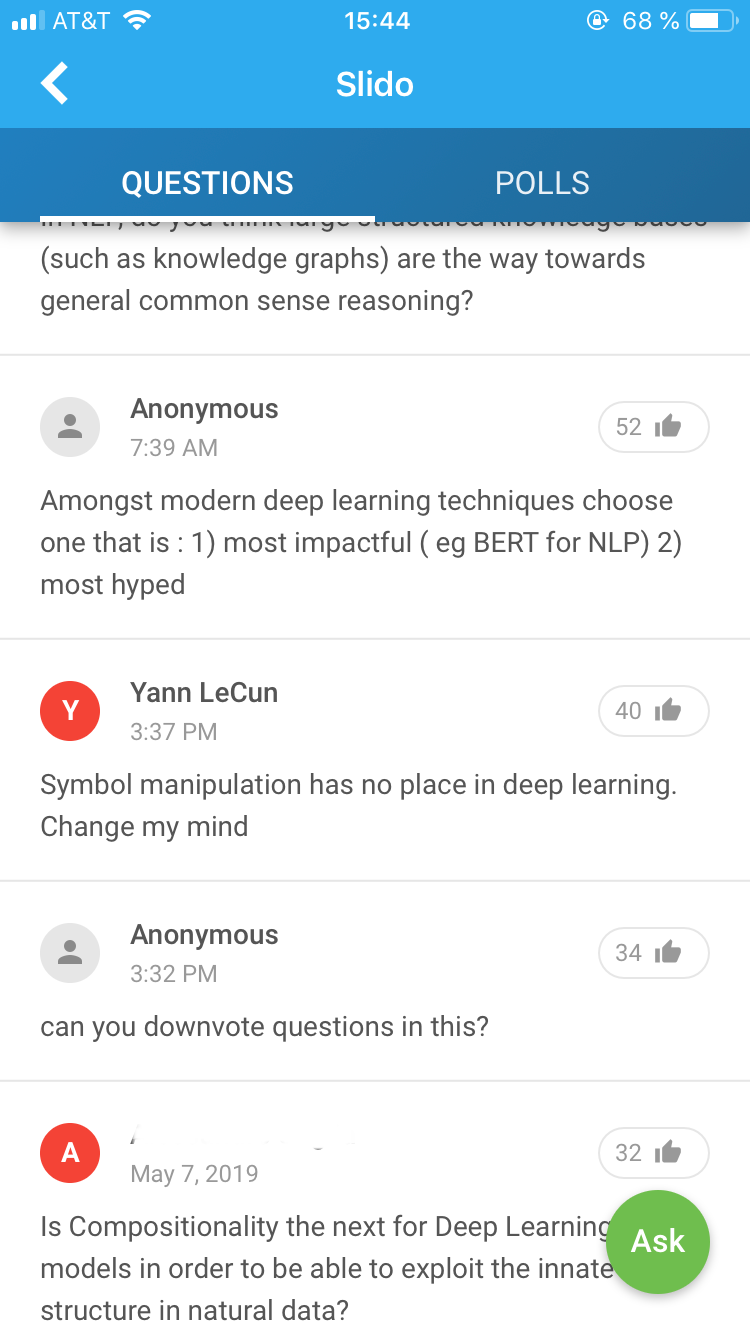
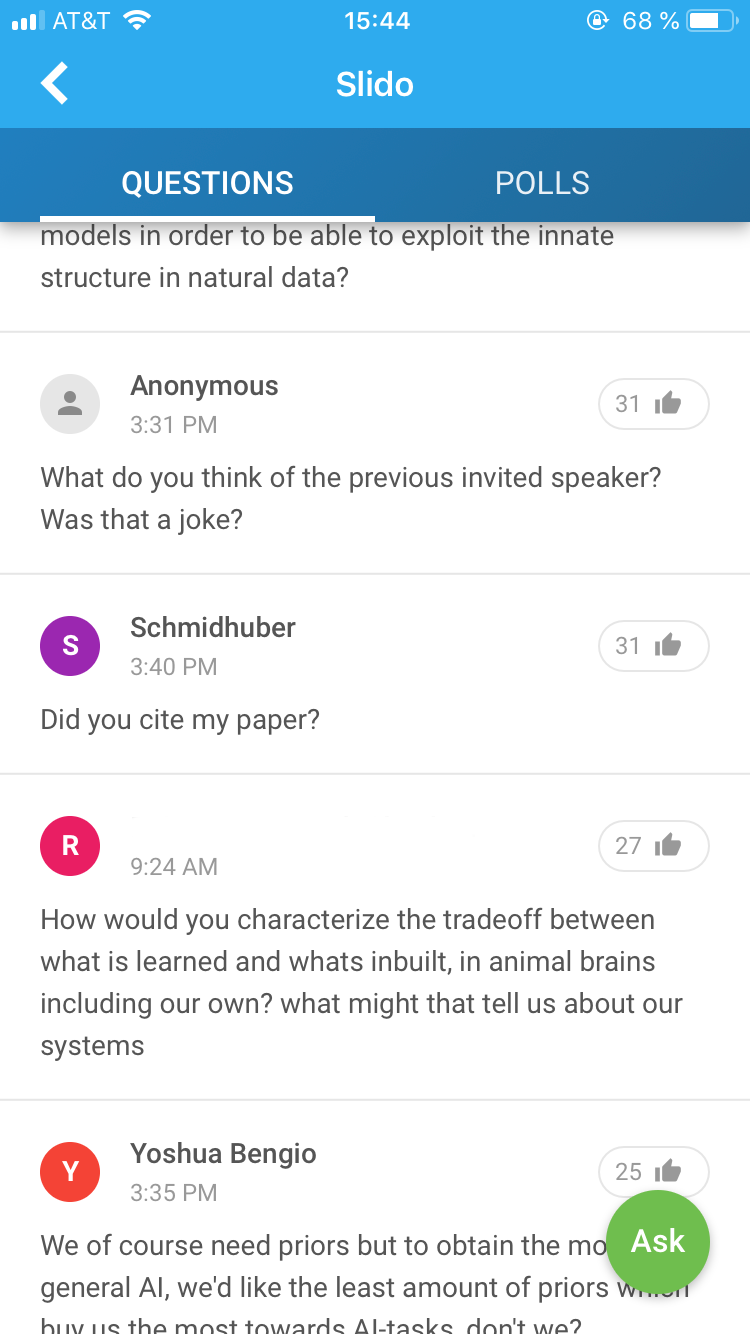
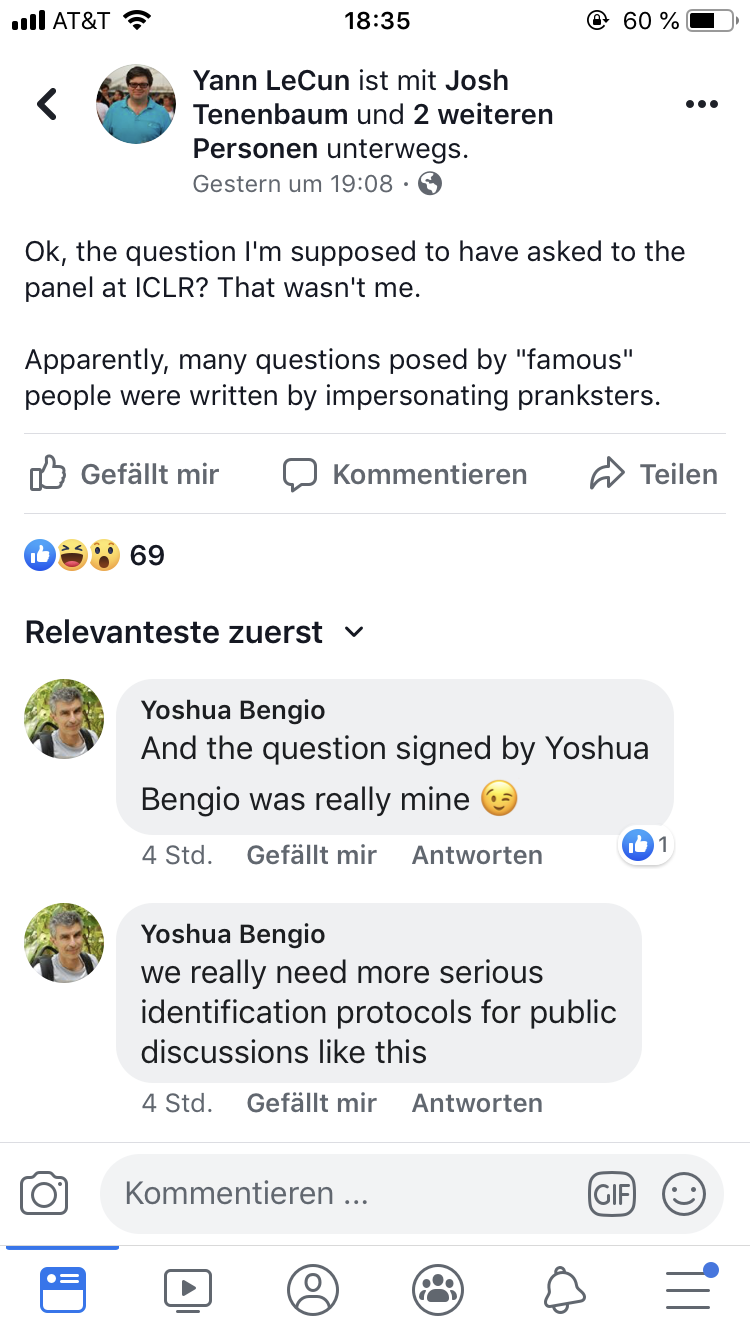
This led to some discussion later on (somewhat ironically) Facebook about data privacy and identity protection. Some people also complained that the panel asked the questions (allegedly) posted by famous persons while ignoring other questions (which had more upvotes). Nevertheless, overall I liked the debate and would like to see events like this more often at conferences.
After the last oral presentation on Thursday afternoon, Yoshua Bengio took the stage and officially announced that the conference will take place in Addis Ababa (Ethiopia) next year to foster inclusivity and to highlight ongoing research in Africa.

The conference concluded with a reception Thursday night with an open bar and food, including some specialties such as New Orleans Pralines and Bread Pudding. Overall, I really enjoyed the conference, its high-quality presentations and posters, the invited keynote speakers, and the chance to talk to both academic and industrial researchers. Read on to get a summary of the keynotes and the ICLR debate in the next part, as well as an overview of some papers I found particularly interesting in the third part.
Papers I Liked
On Monday there were only oral presentations, but no posters (because of the workshops). Two of the oral presentations were about generative models and image generation: BigGAN showed that making GANs larger and increasing the batch size can drastically improve the image quality (Dogball anyone?), while this work introduced some new tricks for autoregressive models for synthesizing large images in an unconditional way. In the afternoon, there was a presentation on how powerful Graph Neural Networks are (hint: under certain conditions as powerful as the Weisfeiler-Lehman graph isomorphism test).
Finally, we had a presentation on one of the two papers that received a best paper award: the Lottery Ticket Hypothesis. It is common knowledge that most (large) neural networks don’t need to be that large to actually reach good performance. In fact, by pruning a large, trained neural network (e.g. by removing connections with small weights) we can usually reduce the size of the network considerably without a loss in performance. However, a puzzling observation so far was that we can not simply take the smaller, pruned network and train it from scratch. One of the main observations in the paper is that we can actually retrain the pruned network from scratch (and the retrained network can even achieve better performance than the original, larger network) if we initialize the weights of the leftover connections to the exact same initial values as in the original network (instead of initializing them randomly). Follow-up work on this has shown that it might actually be the sign of the initial weight that is most important, not the exact value. While this is interesting work, one problem remains: we still have no way of “finding” the trainable sub-network a-priori, i.e. we still need to train the large network first to find the small network. Concurrent work also presented at the ICLR obtains similar results, but shows that for structured pruning algorithms (e.g. channel or kernel wise pruning) one can train the smaller network from scratch even with a random weight initialization. This indicates that it is the architecture of the pruned network (not the preserved weights) that is most important for the final performance.
Best Paper Award 1: The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Jonathan Frankle · Michael Carbin pic.twitter.com/SWVZuekobQ— ICLR 2019 (@iclr2019) 6. Mai 2019
On Tuesday we saw an oral presentation about Slalom which proposes a way to outsource inference with (large) neural networks into the cloud while preserving integrity and privacy. To achieve this, linear computations in neural networks (e.g. matrix multiplications) are outsourced into the cloud for increased speed, while all other necessary computations (e.g. applying non-linearities) are performed in-house on trusted hardware. The outsourced linear operations are protected by cryptographic means and since large matrix multiplications can now be processed on fast (external) hardware this drastically speeds up the inference compared to doing everything in-house on slower hardware. However, while this approach is suitable for inference it is still not fast enough to do actual training of (large) neural nets.
Two other oral presentations were about the topic what CNNs actually learn in typical training procedures. While traditional textbooks teach us that CNNs learn low-level features (such edges and corners) which are then combined to more high-level features in the higher CNN layers both these works actually show that CNNs are typically much more focused on superficial image statistics such as texture instead of focusing on actual shapes in the image. Both approaches then proceed to work towards solving this issue, e.g. by learning to ignore superficial image statistics in the classification process or by making the CNNs more biased towards shape and less biased to textures in the image.
Is object recognition using ConvNets biased to texture rather than shape? #ICLR2019 pic.twitter.com/eRmr8lF0A4— Kosta Derpanis (@CSProfKGD) 7. Mai 2019
Tuesday’s poster sessions were focused a lot on GANs, adversarial attacks/defenses, and general robustness. The Relativistic GAN presents a simple modification to the GAN training that seems to help with training stability. A generative approach for classification promises adversarial robustness on the MNIST dataset (but is quite slow at inference), while other work suggests that robustness might be at odds with accuracy (adversarial data augmentation, while helpful when only little data is available, might be detrimental when we already have a lot of training data). GANs are still hard to evaluate and testing whether the model learned to model the complete data distribution instead of only modeling certain modes of it might be intractable in normal circumstances.
On Wednesday we saw an oral presentation about Deep InfoMAX, a promising way for unsupervised representation learning by maximizing the mutual information between the input and its learned representation. This is motivated by the observation that traditional unsupervised representation learning approaches (e.g. using the learned representation of a VAE) do often not learn optimal representations for downstream tasks. A closer look at few-shot classification shows that many papers do not evaluate baselines for few-shot classification fairly and that simple baselines can perform just as good as more complex approaches.
Deep InfoMax (DIM) is a method for learning unsupervised representations by estimating and maximizing mutual information. There will be a talk at 9:45am today at #ICLR2019 and you can visit our poster at the morning session from 11am to 1pm. pic.twitter.com/LNFJVL86Co— Devon Hjelm (@devon_hjelm) 8. Mai 2019
This study indicates that a large subset of current datasets is not very important for generalization and that a small subset of important examples are most relevant for the final performance. They define a “forgetting event” as the case when a previously correctly classified training example gets classified incorrectly during training and then divide datasets into two subsets: “unforgettable” examples, which are always classified correctly once the network has learned them, and “forgettable” examples, which can transition from being classified correctly to being classified incorrectly over the course of training. They then show that the forgettable examples are much more important and informative for the overall model performance, while unforgettable examples can be removed from the dataset without a large effect on final performance. Related to this, another case study shows that many approaches for preventing catastrophic forgetting (when a model forgets to perform a previous task when trained on a novel task) do not perform very well under real live assumptions such as: future tasks are not known when choosing the model architecture, past data cannot be stored and used for retraining, and retraining complexity should not depend on the number of previous sub-tasks (i.e. you can’t simply store all previous tasks and retrain on all tasks when a new task starts).
Two papers examined L2 regularization and weight decay and showed that they are not the same (at least not the way they are currently implemented in frameworks like Tensorflow and PyTorch). One paper explicitly studies the effects of weight decay in current optimizers such as Adam and SGD. The first observation is that weight decay should have no regularization effects when Batch Normalization (BN) layers are used since BN rescales the outputs of the layers so that the outputs are essentially independent of the scale of the weights. Instead, they found that the way weight regularization works with BN layers is by increasing the effective learning rate which in turn increases the regularization effect of gradient noise. Similarly, decoupled weight decay shows that the way that weight decay is currently implemented in frameworks like Tensorflow and PyTorch leads to interactions between the learning rate and the weight decay penalty. This leads to correlations between the two parameters (which can make hyperparameter optimization more difficult) and can reduce the overall performance (especially for Adam, which uses dynamic learning rates for different parameters). Decoupling the weight decay from the loss function (and thereby the learning rate) fixes this, makes the learning rate independent from the weight decay penalty, and leads to overall better generalization, especially for Adam. So if you are using Adam or SGD optimizers with weight decay, try using AdamW or SGDW and it might help with your model’s performance.
AdaBound promises to combine the strengths of Adam (fast convergence) and SGD (better generalization) to yield the “ultimate” optimizer. A PyTorch implementation by the authors is available, so give it a try. Fixup initialization promises a new approach for weight initialization that allows for residual learning with deep networks without using normalization layers. A mean field theory of Batch Normalization shows that wide, deep neural nets with BN layers but without residual connections suffer from exploding gradients when the weights are randomly initialized, regardless of the used activation function. To fix this we can either continue to use residual connections or increase the \(\epsilon\) value in the denominator of the BN scaling function.
I'm presenting my paper of AdaBound https://t.co/5Dt61FR36g at #ICLR2019 on Wednesday 4:30--6:30 pm. Drop by the poster if you like! pic.twitter.com/la4ja3NGBl— Liangchen Luo (@LiangchenLuo) 6. Mai 2019
Generalization of simple (spatial) relations is still an open issue for neural networks. Typical feed-forward networks like the RelationalNet, FiLM, and MAC can not generalize learned relations to novel inputs. Modular networks, however, are able to generalize these relations but only if the modular layout is carefully tuned to the specific task at hand. Automatically finding the modular layout for a task for which we do not know the underlying distribution and exactly what kinds of relations it contains continues to be a challenge though. Another work shows that there are many consistent explanations of unlabeled data with the following observation: when training a semi-supervised model (such as e.g. the Mean-Teacher model) to models weights tend to change even after the training has converged, meaning the model’s parameters change even though the model’s accuracy does not improve anymore. Motivated by this, the authors suggest to continue training a semi-supervised model even after it converged and to average the weights of the trained model over the last epochs in training to further increase the final performance.
Attending @iclr2019? Check out our poster "There are many consistent explanations of unlabeled data: why you should average". It's TODAY, 4:30 pm - 6:30 pm, Great Hall BC 27! Joint work with B. Athiwaratkun, @m_finzi, @Pavel_Izmailov. Paper: https://t.co/5dRLFqgJlh pic.twitter.com/WIZCg3pzLh— Andrew Gordon Wilson (@andrewgwils) 8. Mai 2019
On the last day of the conference, researchers introduced a new way of using convolution for NLP. The final (sort of convolutional) net reaches the same performance as a state-of-the-art Transformer model on several NLP tasks while being able to perform inference much faster than the Transformer model. The second paper that got a best paper award presented an extension for LSTMs that introduces an inductive bias to model tree structures with LSTMs.
ICLR Best Paper 2: Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks
Yikang Shen · Shawn Tan · Alessandro Sordoni · Aaron Courville pic.twitter.com/BiX4rWc1Ol— ICLR 2019 (@iclr2019) 9. Mai 2019
Meta-learning and transfer learning are still a big topic. Google AI introduces Meta-Learning Update Rules for Unsupervised Representation Learning in which they learn the learning rule for the unsupervised pretraining instead of using a predefined, hand-constructed loss such as the reconstruction loss. In an inner loop, a model (e.g. a MLP) learns the update rule for the weights of the trained model (e.g. a CNN). The trained model from the inner loop (e.g. the CNN) is then evaluated on the downstream task for which it was pretrained (e.g. classification) and the resulting performance is used to train the learning rule (e.g. the MLP) of the inner loop. While this is a promising approach for pretraining it is computationally very expensive and therefore probably not applicable for any real-world tasks. Transferring Knowledge across Learning Processes is a transfer learning approach that tries to transform knowledge across tasks not in the parameter space (as most transfer learning approaches do), but instead try to transfer the knowledge across learning processes. For this, they associate different tasks on which the pretraining takes place with their final solution in the model’s parameter space. The meta-learning objective is then to find a weight initialization that minimizes the distance between the initial weights and the final (learned) weights for the different tasks. The goal is to find a way to initialize the weights of a model in a way that they are as close as possible to the final optimal solution for a given downstream task.
The neuro-symbolic concept learner combines symbolic and sub-symbolic approaches for visual reasoning and performs well even when trained on only 10% of the training data. However, it does still not generalize to unseen combinations of objects and relations. Generative question answering tries to improve the performance on QA by introducing a combination of a generative approach (model the question based on the input data and the answer) and a discriminative approach (what is the answer, given the input and the question). Somewhat surprisingly generative models can suffer from the same problem as discriminative models in that they can not easily detect out-of-distribution samples. In fact, several of the tested generative models (flow-based, VAE, PixelCNN) assign a higher probability to test datasets from a different distribution (e.g. SVHN) than to the test set corresponding to the training set they were trained on (e.g. CIFAR-10).
Attending @iclr2019? Interested in uncertainty, generative models and out-of-distribution robustness? Check out our poster "Do deep generative models know what they don't know?" this Thursday 430-630pm (Joint work with @eric_nalisnick @amatsukawa @yeewhye & Dilan @DeepMindAI) pic.twitter.com/h8IlqtO22d— Balaji Lakshminarayanan (@balajiln) 6. Mai 2019
This sums up my (high-level) overview of some (but by no means all) interesting papers from the ICLR 2019. If you’re interested in other accepted papers check out the ICLR website, check out the OpenReview explorer, or use this search engine to filter for keywords.
Let me know in the comments below about any other cool papers or events that I did not mention.